
Java/Kotlin에서 ArrayList와 Array의 성능 비교하기
최근에 코틀린으로 알고리즘 문제를 풀면서, 같은 문제를 같은 알고리즘으로 풀었지만 ArrayList와 Array 둘 중 어떤 것을 사용하는지에 따라 시간 초과 여부가 달라지는 경우를 확인했습니다. 이번 기회에 ArrayList와 Array의 성능 차이가 어느 정도 나고, 왜 나는지, 그리고 이 차이가 얼마나 중요할지에 대해 공부하면서 글로 정리해 보았습니다.
문제
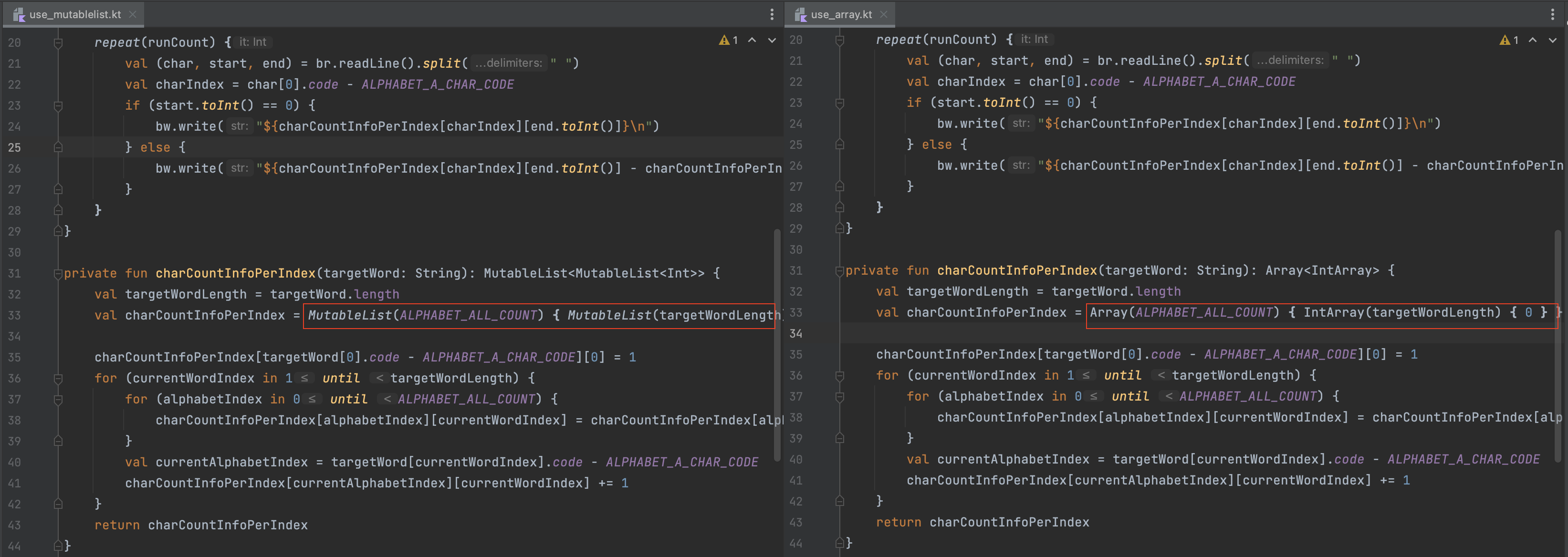
ArrayList와 Array의 선택이 문제가 되는 코드는 아래와 같았습니다. 해당 문제는 백준 16139번 문제에 대한 풀이이고, 전체 코드는 링크에서도 확인해 볼 수 있습니다. 링크 - ArrayList / 링크 - Array
위 코드에서는 MutableList와 IntArray를 사용했는데, 이 두 키워드에 대해 빠르게 살펴보자면:
- MutableList는 코틀린에서 가변 길이 배열을 선언하기 위한 함수이고, 내부적으로는 java의 ArrayList를 사용합니다. (따라서 MutableList를 사용한 것을 ArrayList를 사용한 것과 동일하게 보았습니다.)

- IntArray는 코틀린에서 자바의
int[]와 같은 int 배열을 선언하기 위한 클래스입니다.

코드의 알고리즘 부분을 차치하고 배열 접근과 관련된 부분에 대해서만 설명하자면: 해당 문제는 26개의 원소를 담은 정수 배열을 20만개 만들어서 각각의 원소에 값을 저장한 후에, 다시 그 정수 배열에서 숫자를 20만번 가져오는 문제였습니다. 핵심은 코드 스크린샷에 빨간색으로 표기한, charCountInfoPerIndex 배열의 자료구조를 선언하는 부분입니다. 이 부분에서 MutableList를 사용하면 시간초과의 결과를 받고, IntArray를 사용하면 정답 결과를 받았습니다.
성능 측정하기
정확히 성능 차이가 어느 정도로 발생하는지 확인하기 위해, 직접 해당 문제에 대한 최대 테스크케이스를 만들고, 로컬에서 mutableList를 사용했을 때와, Array를 사용했을 때 각각 시간이 얼마나 걸리는지 측정해 보았습니다.

측정 결과, ArrayList를 사용하는 코드가 0.81초 동안 실행되었고, Array를 쓰는 코드보다 약 15% 더 오래 실행된 것을 확인할 수 있었습니다.
성능 차이의 이유
이러한 성능 차이가 발생한 이유를 찾아보기 위해 여러 자료를 찾아본 결과, 성능 차이의 원인 중 하나로 Java Generic의 Type Erasure / 캐스팅과 관련한 정보를 알 수 있었습니다.
자바(그리고 코틀린)의 제네릭은 Type Erasure를 통해 구현됩니다. 이는 즉 ArrayList
이는 ArrayList의 소스 코드에서도 확인할 수 있습니다. ArrayList의 소스 코드를 보면, 생성자에서는 Object의 배열을 생성하고, 원소를 가져오는 elementData 함수에서는 Object 배열에서 원소를 가져온 후 다시 우리가 필요한 타입으로 캐스팅을 진행합니다.
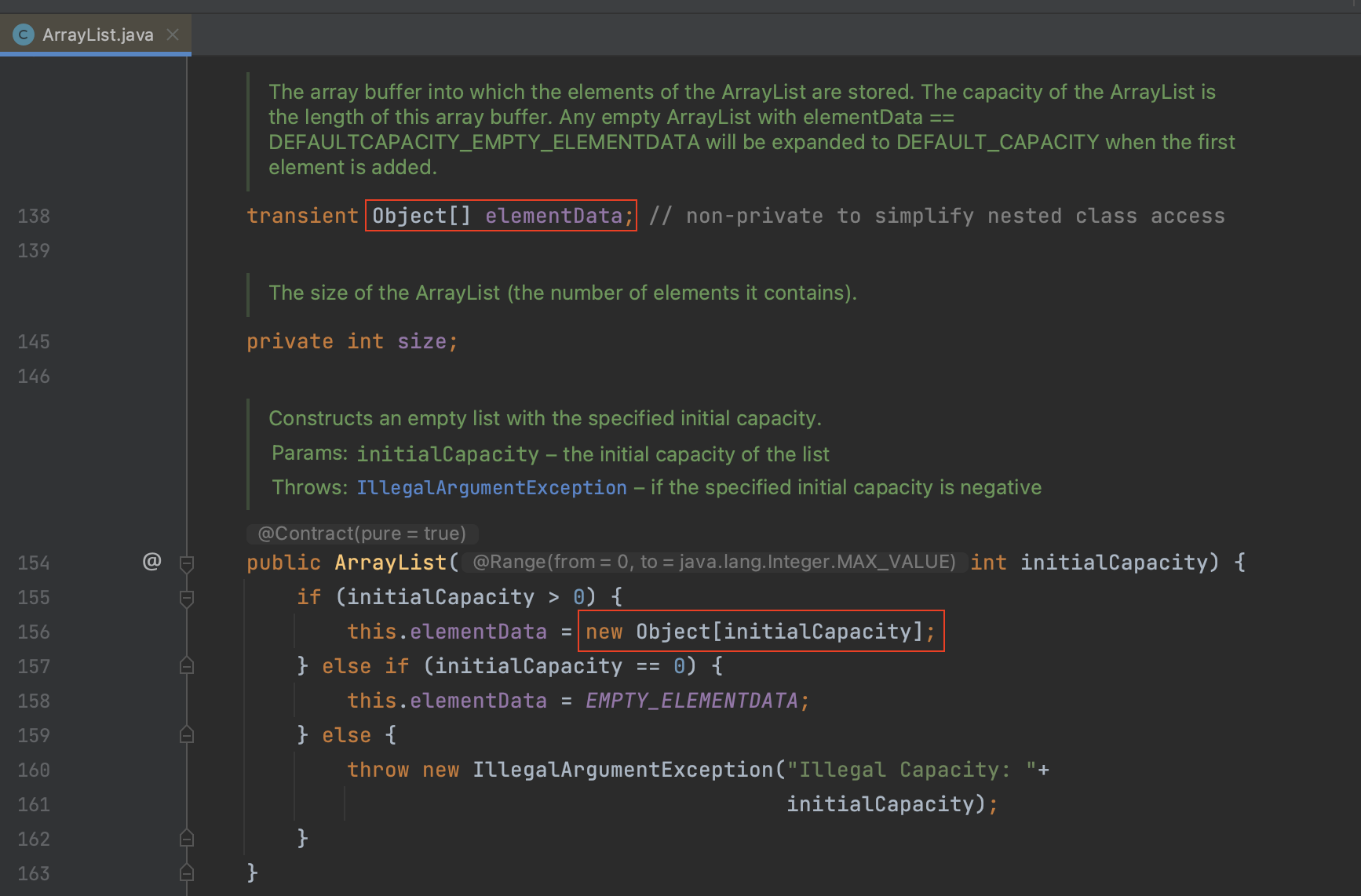
ArrayList의 생성자.
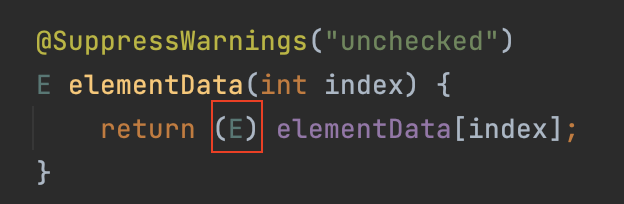
ArrayList의 원소에 접근할 때 쓰이는 내부 함수인 elementData.
Java에서 캐스팅을 진행할 때, 먼저 Object가 우리가 캐스팅하고자 하는 클래스와 실제로 일치하는지 확인하는 과정을 거치고, 일치하지 않는다면 ClassCastException 이 발생하게 되고, 이런 일련의 과정에서 오버헤드가 발생합니다.
성능 차이의 중요성
이 정도의 성능 차이는 실제로 정수 배열을 사용하는 어플리케이션에서 얼마나 중요할까요? 아마 이 차이를 신경써야 할 상황은 매우 적을 것이라 생각합니다.
먼저, 이 문제에서는 20만 개에 달하는 아주 많은 개수의 정수 배열을 다뤄야 하기에, 정수 배열 자료구조의 매우 작은 오버헤드도 전체 실행시간에 유의미한 영향을 끼칠 수 있었지만, 실제 어플리케이션에서는 이렇게 큰 배열을 다루는 경우는 매우 드물 것입니다. 이 문제에서 20만 개의 배열을 다룰 때에조차 전체 수행 시간이 0.1초 내외로 바뀌는 것을 보았을 때는, 실제 어플리케이션에서 더 적은 수의 정수 배열을 다룬다면 절대적인 시간 차이는 더욱 미미할 것입니다.
또한, 알고리즘 문제의 코드는 데이터를 로컬에 있는 파일에서 가져오기 때문에 오버헤드가 적어서, 데이터를 처리하는 과정의 오버헤드가 더 유의미하게 드러날 것입니다. 반면 실제 어플리케이션에서는 대부분 데이터를 외부 네트워크를 통해, 또는 데이터베이스에서 가져오는 과정이 있어, 해당 부분의 오버헤드까지 같이 고려한다면 정수 배열의 오버헤드가 전체 실행 시간에서 차지하는 비중은 더욱 작을 것입니다.
비록 대부분의 상황에서 이 정도의 성능 차이는 무시할 수 있는 수준이겠지만, 이번 기회에 Java의 제네릭과 Type Erasure에 대해 학습하면서, 그래도 충분히 큰 데이터를 다룰 때에는 이런 오버헤드의 원인을 아는 것이 문제를 해결하는 데에 중요할 수 있겠다는 생각을 해 보았습니다.
레퍼런스
StackOverflow - Are ArrayLists more than twice as slow as arrays?
Comments